A* and the 8-Puzzle Game
Use Artificial Intelligence to solve the puzzle you created
by Hanson Schmidt-Cornelius
This lesson introduces the Heuristic Search Algorithm A* (A Star) and uses it to solve the 8-Puzzle. A high level discussion of key algorithm components is given, and code samples are provided. Further research into the A* algorithm is strongly advised. You can dowload the complete code for this article here.
Introduction
Prior knowledge of lesson How do I Create an 8-Puzzle Game? is essential and an understanding of lesson How do I Tell the Computer to Solve the 8-Puzzle Game? would be an advantage. The brute force algorithm discussed in How do I Tell the Computer to Solve the 8-Puzzle Game? is not relevant to this lesson but should provide you with an alternative view on how to solve puzzles like the 8-Puzzle.
A* (A Star) is a state space search algorithm that makes informed judgements about the cost involved in solving the puzzle. Two fundamental values feed into assessing the cost of a particular move on the board:
g: is the number of tiles that have moved to reach a board state that is being assessed
h: is the estimated cost to solve the board state that is currently being assessed
g can be calculated accurately by counting the number of moves we have already taken
h is calculated using a heuristic that provides an underestimating cost to solve the game. The heuristic we use here is called the manhattan distance and calculates by how many squares a tile is displaced from the location that the tile would have to be in to form part of the winning board state.
This gives us the following cost assessment for any state in the search space: f = g + h
Using a heuristic to solve the 8-Puzzle, rather than brute force, as described in How to I Tell the Computer to Solve the 8-Puzzle Game? allows us to find a solution to the puzzle in less time. You can test the algorithms side by side to see the performance difference.
Integrating the Functionality
Please update the openStack code from lesson How do I Create an 8-Puzzle Game? with the following openStack code. This adds a Solve button to the board and populates that button with the RevTalk script to run the A* algorithm. Note that only one comment and one line of code have been added to the original openStack.
on openStack
# set up the constants for the game type
setGameConstants 3, 3
# remove any previous buttons that may already be on the card
# this prevents us from duplicating existing buttons
repeat while the number of buttons of this card > 0
delete button 1 of this card
end repeat
# create the board buttons
createBoard 50
# write the values onto the buttons
writeButtonLabels sWinningState
# create the space on the board
hide button ("b" & sSpaceButton)
# create the shuffle button
createShuffleButton
# create the solve button
createSolveButton
# make sure the board cannot be resized
set resizable of me to false
end openStack
Command createSolveButton creates the solve button and populates the script that is called when pressing the button. This command also resizes the card on which the game buttons and tiles are placed.
command createSolveButton
# create the shuffle button
new button
set label of button "New Button" to "Solve"
set width of button "New Button" to 60 * sTilesX + sOffset * (sTilesX - 1)
set location of button "New Button" to (60 * sTilesX + sOffset * (sTilesX - 1)) / 2 + 20, \
(60 * sTilesY + sOffset * (sTilesY - 1)) + 96
# populate the button script for the shuffle button
set the script of button "New Button" to \
"on mouseUp" & cr & \
"solvePuzzle 50" & cr & \
"end mouseUp"
set the name of button "New Button" to "Solve"
# resize the board for the buttons
set the width of me to 60 * sTilesX + sOffset * (sTilesX - 1) + 40
set the height of me to 60 * sTilesY + sOffset * (sTilesY - 1) + 126
end createSolveButton
Managing the Solution Process
Command solvePuzzle performs all the steps need to solve the 8-Puzzle. This includes testing whether or not the first board state is already the winning board state, calling the cost function costGH and exploreStates to explore the next potential paths that may lead to a solution. pPadding specifies the amount of space that exists between the top and the left edge of the stack cards and the grid tiles.
command solvePuzzle pPadding
local tStatesToExplore, tExploredStates, tMove
# create the first state to explore and calculate its estimated cost
put "," & boardToBoardState (pPadding) into tStatesToExplore
if manhattanDistance (item 2 of tStatesToExplore) is 0 then
answer "Puzzle is Already Solved!" with "OK"
else
put costGH (tStatesToExplore) & "," & tStatesToExplore into tStatesToExplore
repeat until tStatesToExplore is empty
if manhattanDistance (item 3 of line 1 of tStatesToExplore) is 0 then
repeat for each word tMove in item 2 of line 1 tStatesToExplore
swapButtons sSpaceButton, tMove
end repeat
answer "I Made It!" with "OK"
exit repeat
else
exploreStates tStatesToExplore, tExploredStates
end if
end repeat
end if
end solvePuzzle
Exploring Game States
Command exploreStates takes pointers to two lists of states that are to be explored and that have already been explored. This information is important as it allows the search algorithm to make an informed decision as to whether a future new state is better or worse than states that have been visited in the past or states that are to be visited in the future.
command exploreStates @pStatesToExplore, @pExploredStates
local tNewStates, tResult
# get the next possible moves for pStateToExplore
put getNewStatePaths (line 1 of pStatesToExplore) into tNewStates
# move the state path that is being explored to pExploredStates
if pExploredStates is not empty then
put cr after pExploredStates
end if
put line 1 of pStatesToExplore after pExploredStates
# remove the state path that is being explored from pStatesToExplore
put line 2 to -1 of pStatesToExplore into pStatesToExplore
# prune the existing explored and unexplored search space
pruneStateSpace tNewStates, pStatesToExplore, pExploredStates
# sort pStatesToExplore so the cheapest path is located at the beginning
sort lines of pStatesToExplore numeric by item 1 of each
end exploreStates
Getting New States
Function getNewStatePaths produces a list of possible states that can be reached by moving one tile from the most recent state of pPath. pPath is the only parameter passed to this function. All possible next steps are returned by tResult.
function getNewStatePaths pPath
local tPossibleMove, tNewPath, tResult
# we are testing for all possible tile moves
# from the most recent state of the current path
repeat with tPossibleMove = 0 to sSpaceButton - 1
put deriveNextState (pPath, tPossibleMove, sSpaceButton) into tNewPath
if tNewPath is not empty then
if tResult is not empty then
put cr after tResult
end if
put tNewPath after tResult
end if
end repeat
return tResult
end getNewStatePaths
Generating a New State for an Existing Path
Function deriveNextState takes three arguments and tries to add a new state to the path that is passed in by the argument pCurrentPath. pSwap1 and pSwap2 are the tiles that are to be swapped in order to create the new state. If tiles pSwap1 and pSwap2 cannot be swapped, then deriveNextState returns empty.
pCurrentPath and the non empty tResult are comma delimited strings with item 1 containing the current cost f of the path, item 2 containing the individual moves that can later be replayed when solving the 8-Puzzle and items 3 to n containing the individual board states that make up the path that is being explored.
function deriveNextState pCurrentPath, pSwap1, pSwap2
local tHorizontal, tVertical, tButton1H, tButton2H, \
tButton1V, tButton2V, tPossibleNewState, tResult
# get the x and y positions of the two buttons to be swapped
# with respect to the horizontal and vertical game grid of the first
# state of the current path
# we are using item 3 here as item 1 is the cost of the path and
# item 2 contains the moves needed to solve the puzzle
put (wordOffset (pSwap1, item 3 of pCurrentPath) - 1) mod sTilesX into tButton1H
put (wordOffset (pSwap1, item 3 of pCurrentPath) - 1) div sTilesY into tButton1V
put (wordOffset (pSwap2, item 3 of pCurrentPath) - 1) mod sTilesX into tButton2H
put (wordOffset (pSwap2, item 3 of pCurrentPath) - 1) div sTilesY into tButton2V
# determine if the two buttons can be swapped,
# if so create a new state that represents the swap
if ((tButton1H - tButton2H is 0) and (abs (tButton1V - tButton2V) is 1)) or \
((tButton1V - tButton2V is 0) and (abs (tButton1H - tButton2H) is 1)) then
put item 3 pCurrentPath into tPossibleNewState
replace pSwap1 with "X" in tPossibleNewState
replace pSwap2 with pSwap1 in tPossibleNewState
replace "X" with pSwap2 in tPossibleNewState
# check here if we have a loop in the path and reject it if so
if itemOffset (tPossibleNewState, item 3 to -1 of pCurrentPath) is 0 then
# add the new state to the front of other states
put tPossibleNewState & "," & item 3 to -1 of pCurrentPath into tResult
# add the move that got us to this new state to the list of moves we made so far
if item 2 of pCurrentPath is empty then
put pSwap1 & "," & tResult into tResult
else
put item 2 of pCurrentPath && pSwap1 & "," & tResult into tResult
end if
put costGH (tResult) & "," & tResult into tResult
end if
end if
return tResult
end deriveNextState
Calculating f = g + h
Function costGH calculates the cost f for a given path pPath.
function costGH pPath
local tMove, tResult
# calculate g for pPath
repeat for each word tMove in item 1 of pPath
add 1 to tResult
end repeat
# calculate h for pPath and add it to g
add manhattanDistance (item 2 of pPath) to tResult
return tResult
end costGH
Pruning the Search Space
Command pruneStateSpace take a set of paths that are to be explored and tries to add them to pStatesToExplore. A successful add depends on whether or not a potentially better path already exists in pStatesToExplore or pExploredStates. Note that pStatesToExplore and pExploredStates are passed in by reference. This means that any changes made to their content will be permanent and affects their use outside the scope of this command.
command pruneStateSpace pNewPaths, @pStatesToExplore, @pExploredStates
local tPath, tStatesToExploreDuplicate, tExploredStatesDuplicate, tAddFlag
repeat for each line tPath in pNewPaths
put false into tAddFlag
# find out if the new state to explore exists
# as a head in one of the already explored states
put stateMatch (tPath, pExploredStates) into tExploredStatesDuplicate
# find out if the new state to explore exists
# as a head in one of the states that are still to be explored
put stateMatch (tPath, pStatesToExplore) into tStatesToExploreDuplicate
if tExploredStatesDuplicate is false and tStatesToExploreDuplicate is false then
# if we found no match, then set a flag to add the new path
# to the paths that are to be explored
put true into tAddFlag
else if tExploredStatesDuplicate is not false and item 1 of tPath < \
item 1 of line tExploredStatesDuplicate of pExploredStates then
# if we found a match with the states we already explored and the new path
# is cheaper then remove the matched state from the explored states
# and set the flag to add the new path to the paths that are to be explored
delete line tExploredStatesDuplicate of pExploredStates
put true into tAddFlag
else if tStatesToExploreDuplicate is not false and item 1 of tPath < \
item 1 of line tStatesToExploreDuplicate of pStatesToExplore then
# if we found a match with the states we have not yet explored and the new path
# is cheaper then remove the matched state from the unexplored states
# and set the flag to add the new path to the paths that are to be explored
delete line tStatesToExploreDuplicate of pStatesToExplore
put true into tAddFlag
end if
# if tAddFlag is set then add the new path to the paths that are to be explored
# any new paths that exist for which tAddFlag is not set to true are skipped
if tAddFlag is true then
if pStatesToExplore is not empty then
put cr after pStatesToExplore
end if
put tPath after pStatesToExplore
end if
end repeat
end pruneStateSpace
Function stateMatch tests whether or not the most recent state in a new path matches one of the most recent states in a list of paths. This function returns false if no match was found or the location where the path match was found.
function stateMatch pPath, pPathList
local tPath, tLineCount
repeat for each line tPath in pPathList
add 1 to tLineCount
if item 3 of tPath is item 3 of pPath then
return tLineCount
end if
end repeat
return false
end stateMatch
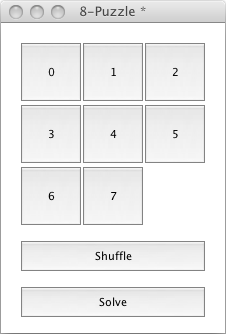
The 8-Puzzle Board (Ready to Play)
The puzzle interface from this lesson works in the same way as the puzzle interface from lesson How do I Tell the Computer to Solve the 8-Puzzle?. The only difference is that the label on the Solve button does not change. This is because the search algorithm is iterative, rather than recursive and we are not exploring the search space in a depth first fashion.
|
About the Author
Hanson Schmidt-Cornelius is an experienced software developer with an interest in artificial intelligence.
|



|
|